RNS TPU™ : A Breakthrough in Matrix Computation for AI
The RNS TPUTM is the only hardware matrix multiplier that performs arithmetic entirely in the Residue Number System (RNS) – delivering un-matched speed, precision, and efficiency. Unlike traditional AI accelerators, RNS TPUTM doesn’t rely on approximate math and doesn’t sacrifice accuracy for speed. RNS TPUTM targets niche neural network training applications requiring FP32 or FP64 level precision, such as Physics Inspired Neural Networks (PINNs), Financial Forecasting and Time-Series Models, Astronomy and Deep Space AI, Chaotic Systems and Quantum AI and Simulation.
Interface Model : F32 -> Modular Math -> FP32
The RNS TPU™ uses a floating point interface:
- Input values begin in standard FP64, FP32/BFP16, or FP16
- Values internally converted to 32.32 fixed-point RNS format
- Matrix multiplication occurs entirely in reside space, across independent “Digit Matrix Multipliers”
- Final results are converted back to FP64, FP32/BFP16 or FP16 for compatibility with existing AI training infrastructure

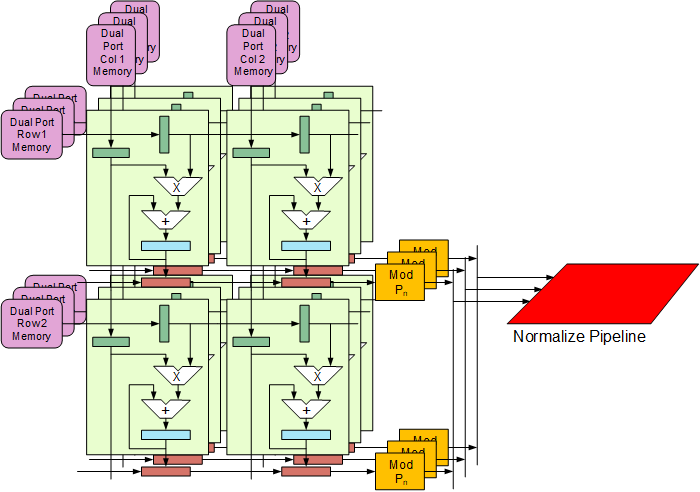
Architecture Details of the RNS TPUTM
The RNS TPU™ uses a radically unique architecture:
- Eight digit RNS word is divided into eight parallel digit matrix multipliers.
- Carry-Free Accumulation: No carry chains for accumulation – all accumulation is modular arithmetic.
- Carry-Free Multiplication: Like addition, multiplication is also carried out in parallel, without carry and using modular arithmetic.
- Digit-sliced Architecture: Each matrix product accumulator is distributed across high-speed, parallel RNS “digit” TPUs.
- Systolic Execution: Single pass data processing; matrix products accumulated in-place with no off-TPU buffering.
Ideal Neural Network Training Tasks
The RNS TPUTM is particularly suited for tasks that need extended dynamic range and/or high-precision training:
- Deep CNN Layers with high resolution convolution filters
- Reinforcement learning, including RLHF and reward modeling
- Scientific and physics-informed models where precision matters
- Financial and forecasting networks with long sequences and wide ranges
- Quantum simulation or Q64.64 emulation with extended residue digits
Evaluate our Technology – Immediately Deployable
RNS-TPUTM IP cores are optimized for Intel:
• Arria-10
• Stratix-10
• Agilex Families
Turnkey demos are immediately available for Intel FPGA development platforms from Terasic. Our IP supports Intel and Xilinx devices and is ready to drop into your system or research.

Access our public RNS-TPU research papers
Access our RNS-TPU via the cloud!
Preliminary Specifications for Arria 10 based RNS TPU 1.0
* RNS TPU™ is a trademark of MaiTRIX, LLC
*Arria, Stratix and Agilex are trademarks of Intel Corporation.